序列前置知识之高级配置
相信眼尖的师傅们发现了,在上篇教程中还有一些高级配置的功能没有讲解,这篇教程我们就来讲解一下这些高级配置的功能。
我们为什么要拆开两篇文章来讲解呢?因为这些高级配置的功能,涉及到后续教程讲解的一个大功能:Web Fuzzer序列。在我们讲解Web Fuzzer序列之前,我们需要先了解一下剩余的高级配置的知识。
匹配器#

我们先看一共有三种匹配模式:丢弃,保留,仅匹配。这三个模式很好理解:
- 丢弃:丢弃模式会在符合匹配器时下丢弃返回包。
- 保留:保留模式会在符合匹配器时保留返回包,剩余的返回包则直接丢弃。
- 仅匹配:仅匹配模式会在符合匹配器时将对应的返回包染色,而不做其他操作。
在匹配模式的旁边,有一个红色的圈,这里实际上是颜色按钮,用于设置在仅匹配模式下的染色颜色。
再往右看,有两个二选一按钮:AND和OR。这两个按钮用于设置多个数据提取器的匹配逻辑,AND表示所有匹配器的条件都需要匹配,OR表示只需要有其中一个条件匹配即可。
接下来我们来讲解一下如何添加匹配器,我们点击下方的添加按钮或者图中右上角的添加/调试按钮,就可以添加匹配器了。
添加匹配器#

匹配器给我们提供了多种匹配类型与匹配位置,方便我们编写复杂的匹配器。
首先我们来介绍匹配类型:
- 关键字:关键字就是在匹配位置中匹配输入的关键字。
- 正则表达式:正则表达式就是在匹配位置中匹配输入的正则表达式。
- 状态码:(忽略匹配位置)状态码就是匹配响应的状态码,我们只需要填写希望匹配到的状态码即可。
- 十六进制:在某些情况下,希望匹配的字符串不是正常可见的ascii码,这时候你就可以使用十六进制这种匹配类型,输入十六进制字符串(例如字符串"302"对应十六进制字符串"333032")。
- 表达式:(忽略匹配位置)表达式可以更加灵活地编写我们所希望的匹配规则,它还能与后续要讲的 高级配置:变量 联动。表达式的语法与nuclei-dsl语法兼容,熟悉nuclei工具的师傅可以尝试在表达式中编写一些复杂的匹配规则。一个匹配响应体中是否存在对应字符串的例子如下:
contains(body,'302 Found')。
然后我们再来介绍匹配位置,我们以下面这个响应包为例:
HTTP/1.1 302 FoundConnection: keep-aliveContent-Type: text/html; charset=utf-8Location: https://www.baidu.com/Content-Length: 154
<html><body>302 Found</body></html>- 状态码:匹配范围仅有状态码。
- 响应头:匹配范围包含响应的第一行(在例子是
HTTP/1.1 302 Found)以及响应头。 - 响应体:匹配范围包含响应正文(在例子里是
<html><body>302 Found</body></html>)。 - 全部响应:匹配范围即整个响应包。
另外匹配器还包含不匹配(取反)这个选项,其意思是将匹配改为不匹配,这方便我们编写更复杂的匹配器。
数据提取器#

数据提取器的功能是将响应包中的某些数据提取出来,我们来讲解一下如何添加数据提取器。
添加数据提取器#
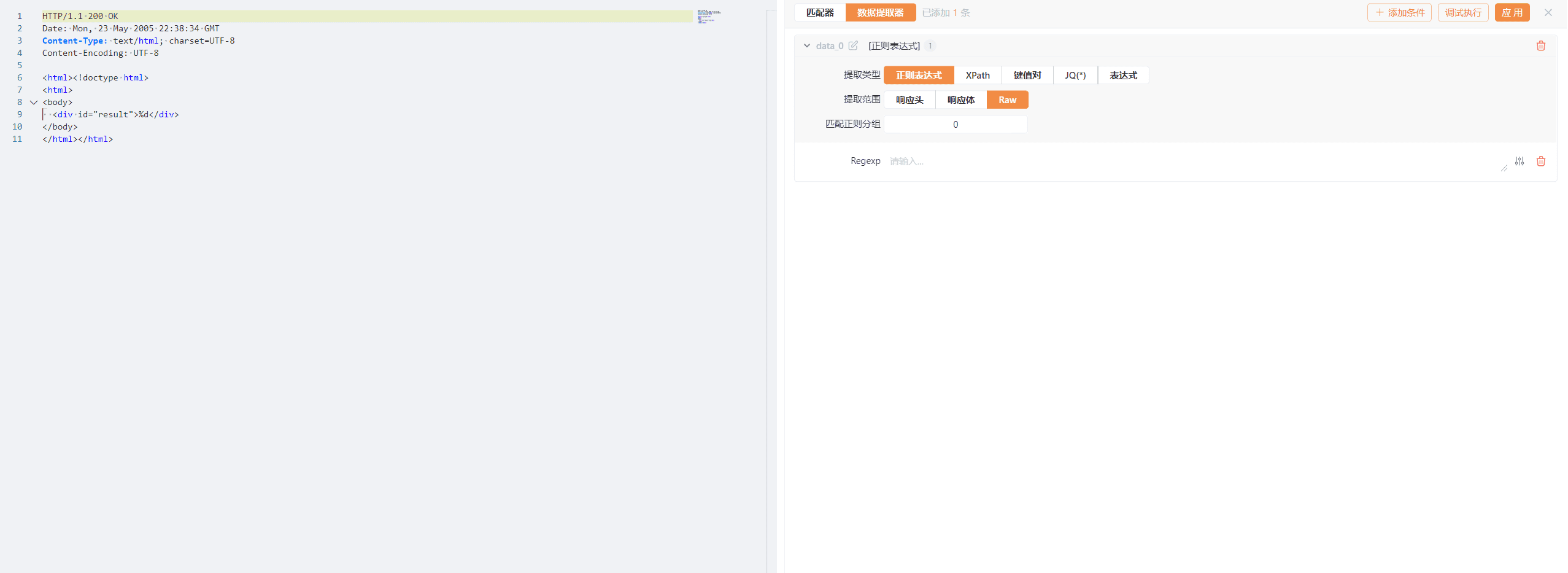
数据提取器同样给我们提供了多种提取类型与提取位置,方便我们编写复杂的数据提取器。我们可以看到在数据提取器的左上角(data_0)旁边存在一个编写按钮,这是用于修改提取器的名字,这个名字可以在后续变量和Web Fuzzer序列中使用。
首先我们来介绍提取类型:
- 正则表达式:正则表达式就是在提取位置中提取输入的正则表达式匹配到的内容。我们知道在正则表达式中可以使用小括号来分组,这时候我们可以在匹配正则分组中选择分组,这样就可以提取到想要的内容了。(在正则表达式中,0分组即为正则表达式匹配到的所有内容)
- XPath:(提取范围只能是响应体)XPath就是在提取位置中提取输入的XPath匹配到的内容。XPath是一种用于在XML文档中选择节点的语言,我们也可以很轻易地使用浏览器开发工具来复制完整的Xpath。
- 键值对:键值对的提取规则稍微有点复杂。键值对会尝试提取所有可能存在的json的key对应的value,以及所有形似
key=value中value的值。如果提取位置包含响应头(提取范围为响应头或Raw),则他还会尝试提取响应头中的value值。另外还有两个特殊的键值对,分别为proto,status_code,分别对应响应的HTTP协议版本和响应状态码。 - JQ(*):(提取范围只能是响应体)jq是一种用于在JSON文档中选择节点的工具,其对应的文档教程在此。
- 表达式:(忽略匹配位置)表达式与上面匹配器中的表达式相同,这里不再赘述。
对于Xpath这种提取类型,我们以下面的例子做讲解:
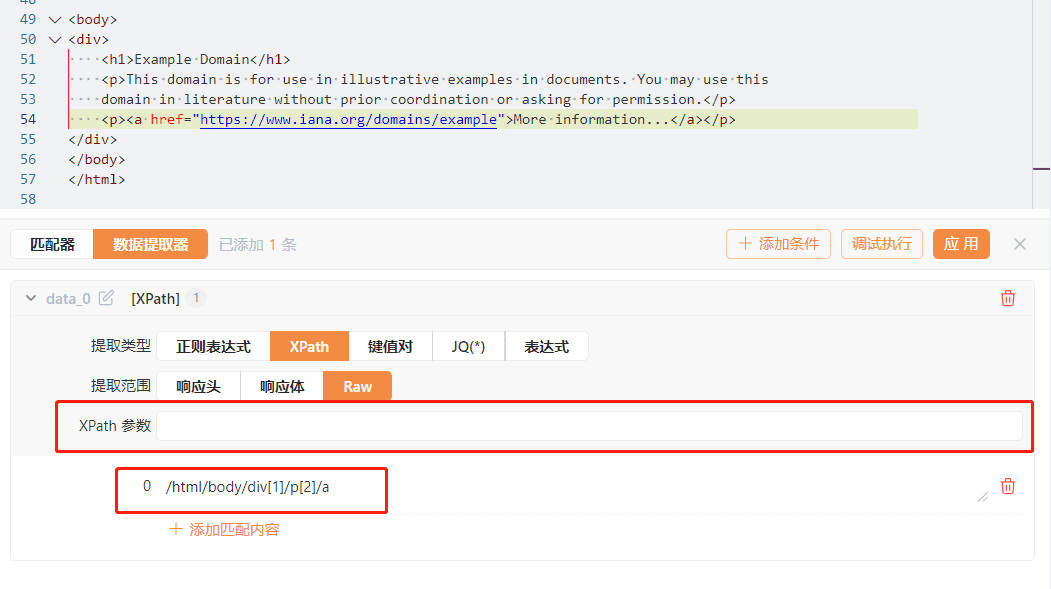
在上述例子中,我们在最下面一行中填入xpath:/html/body/div[1]/p[2]/a,此时如果点击调试执行,我们就可以拿到对应的a标签内容:More information...。假如我们在上面的Xpath 参数中填入href,我们就可以提取到a标签的href属性:https://www.iana.org/domains/example。
对于JQ这种提取类型,我们以下面的例子做讲解:
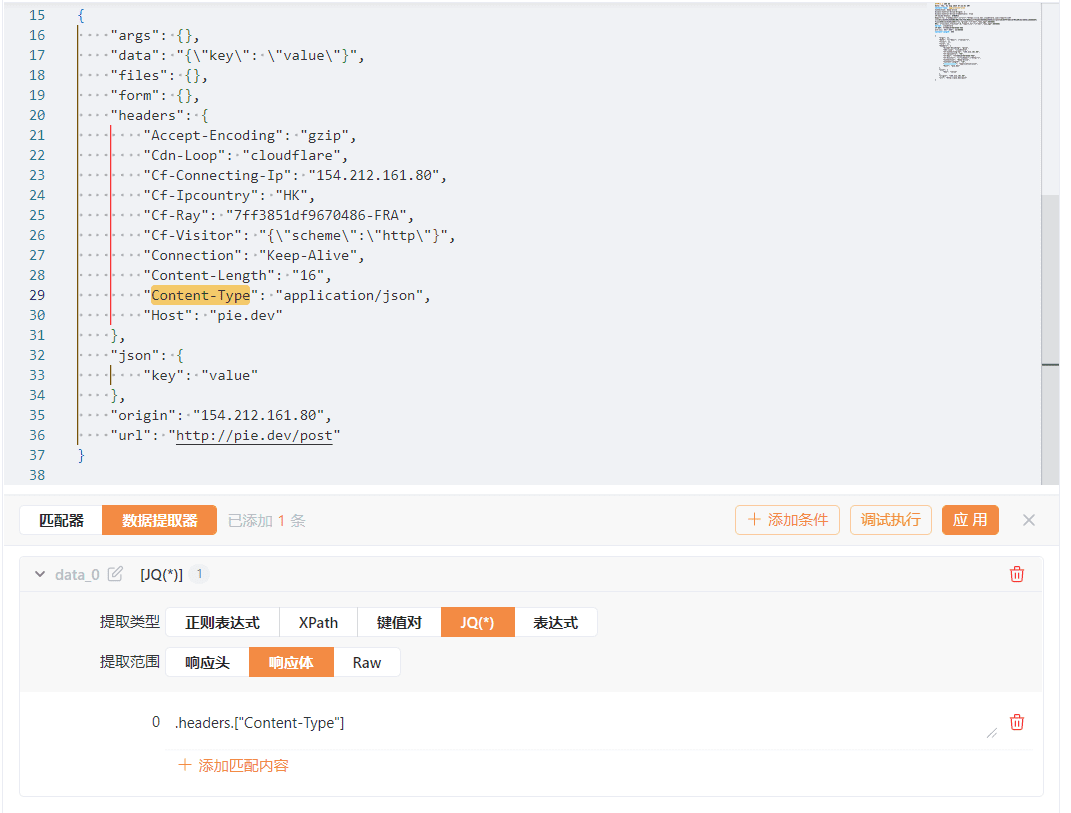
在上述例子中,我们可以看到响应体是一段json。假如我们想提取headers中Content-Type的值,我们只需要使用.headers.["Content-Type"]即可。
变量#

在上述数据提取器小节中,我们提到数据提取器的名字可以在变量中使用,实际上就相当于我们赋值了一个变量。同样地,我们也可以直接在变量这个地方上直接赋值变量。
在上图中,我们可以设置变量名和变量值,变量可以在后续变量,Web Fuzzer序列和当前Web Fuzzer中使用。我们可以通过使用fuzztag:{{params(变量名)}}或{{p(变量名)}}来使用变量。
变量同样存在三种模式:nuclei,fuzztag,raw。
- nuclei:nuclei模式下,其变量值实际上是nuclei的表达式,可以调用绝大部分nuclei-dsl中包含的函数。需要注意的是,当你引用其他变量时,其的值都是string类型,所以可能需要手动进行类型转换。一个简单的例子如下:
{{int(a)+3}}。 - fuzztag:fuzztag模式下,其变量值实际上就是fuzztag,在值中使用fuzztag也会使得Web Fuzzer发送多个请求包。一个简单的例子如下:
{{int(1-2)}}。 - raw:raw模式下,变量值相当于你输入的字符串,不会被解析。
GET 参数 / POST 参数 / Cookie / Header#
这些配置放在一起讲解。设置了这些配置之后,Web Fuzzer会在发送请求包时添加对应的 GET 参数 / POST 参数 / Cookie / Header并且额外发送请求,每设置一个变量就会额外发送一次。
我们以一个简单的例子来说明这个功能:
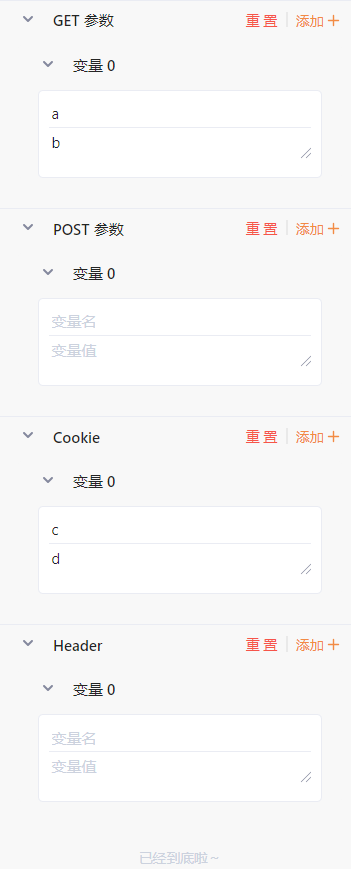
如图所示,我们设置了 GET 参数变量:a=b 以及 Cookie: c=d,当我们点击发送请求时,一共发送了3个请求包:
这三个请求包分别是:
- 原始请求,没有应用任何参数变量。
- 应用了其中一个 GET 参数变量:
a=b,额外发送了一个包含 GET 参数:a=b的请求。 - 应用了其中一个 Cookie 变量:
c=d,额外发送了一个包含 Cookie:c=d的请求。
同理,假如我们额外设置了一个 GET 参数变量:e=f,那么我们就会额外发送一个包含 GET 参数:e=f的请求。